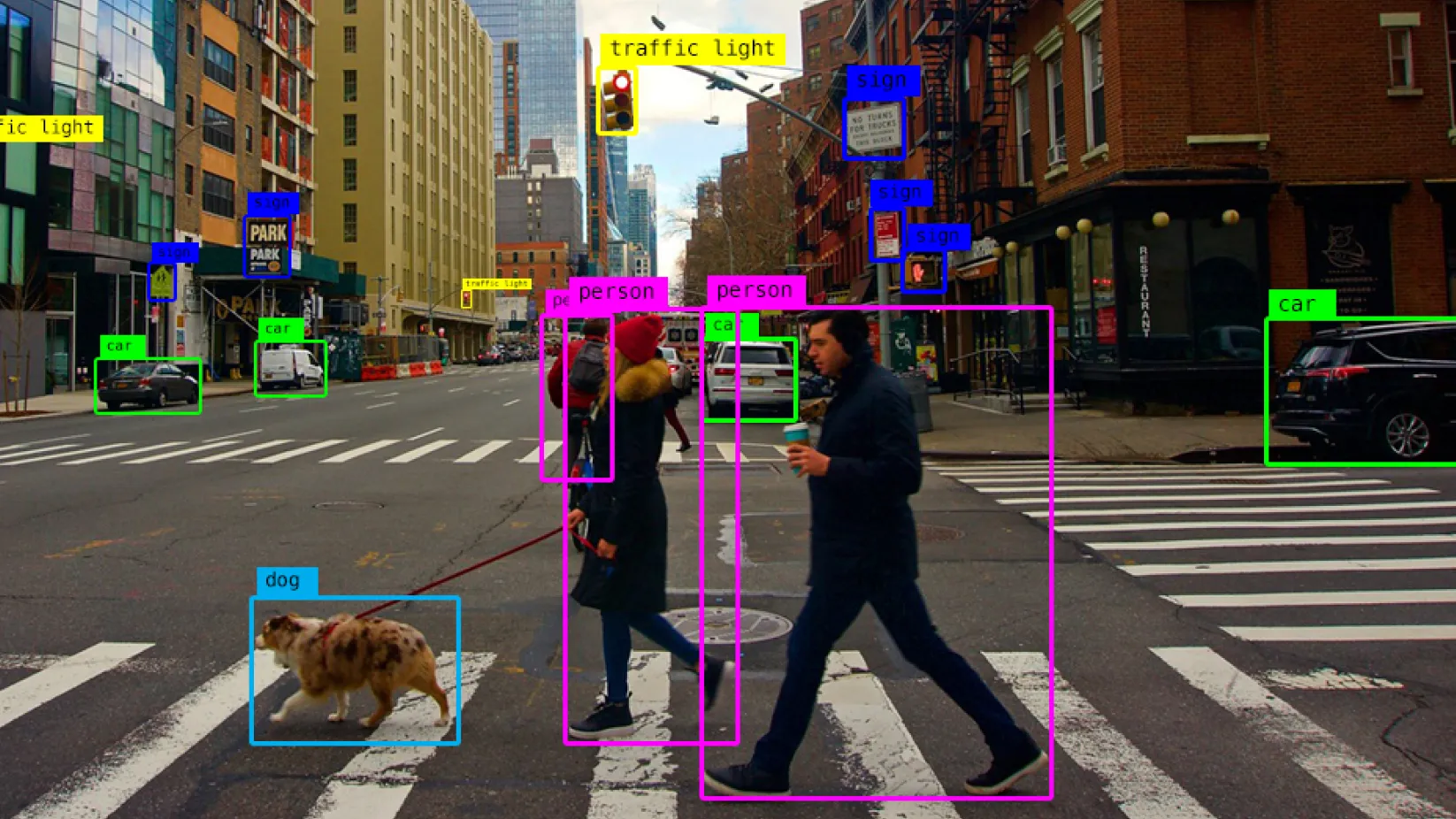
Object Detection
Object detection is a computer vision technique that allows a computer to identify and locate objects within an image. For our applications, this often means identifying game pieces or field elements. There are two common approaches that can be used for object detection: traditional computer vision techniques and deep learning.
Traditional Computer Vision Techniques
Deep Learning Techniques
Deep learning techniques involve the training of a deep learning model on a large dataset of labelled training data, often called a dataset. The data is fed to the model, which uses it to learn important features and patterns that can be used to identify objects in new images.
For computer vision applications, most of the deep learning models use a foundational concept called Convolutional Neural Networks (CNNs). CNNs are designed to process visual data and have proven to be highly effective for image recognition tasks. They use a special mathematical operation called convolution to extract features from images. These convolution operations are able to capture features in the image such as edges, textures, and shapes. Most models use a series of convolutional layers, to allow the network to better learn more complex features and patterns that are important for object detection.
Over the past few years we have used several different deep learning models for object detection, including:
Yolo Models
The You Only Look Once (YOLO) family of models are a series of real-time object detection models that are designed to be fast and accurate. YOLO models work by dividing the input image into a grid and predicting bounding boxes and class probabilities for each grid cell. This allows the model to detect multiple objects in a single pass through the network, making it much faster than traditional object detection methods. This is the model architecture we have selected for the 2024 and 2025 seasons, due to its speed and accuracy.
Model Training
For our deep learning models, we use a two step process to train the models. First we create a dataset in RoboFlow, which is a tool that allows us to create a labelled dataset for training. We have a RoboFlow organization set up for our team. Once the dataset is created, we then use that dataset to train the model using the Ultralytics YOLO training framework. This framework provides a simple interface for training YOLO models from our RoboFlow dataset.
Model Deployment
Once the model is trained, we then deploy the model to our Nvidia Jetson vision computer. Since the Jetson is not as powerful as a desktop computer, we often need to optimize the model for inference on the Jetson. To do this, we use a tool called TensorRT, which is a high-performance deep learning optimizer and runtime library.
First the model must be exported to the ONNX format, which is a standard format for trained deep learning models. ONNX encodes both the model architecture and the learned weights. Once encoded, the model is then fed to TensorRT for optimization. TensorRT Converts the model to a highly optimized runtime that is specifically designed for inference on Nvidia hardware like the Jetson.